Build Identity Trust with the Right Data

More data sources is only part of the equation
In the era of big data, it is often thought that more data is better, but that's not necessarily so. It's not just about having more data, but having the right kind of data. Furthermore, having access to better data sources is only part of the equation. The skill of incorporating information to extract insights and handling uncertainty is just as important, if not more so.
My last blog described how multisource data is necessary to reduce uncertainty in the constantly evolving environment of identity and fraud. Now, we’ll describe some common pitfalls of working with multisource data and how this can impact you.
Even for the experienced analytics professional or data scientist, the journey from data to insights is not an easy path. And it can be extremely challenging when it comes to working with multisource data. There are several factors to deal with. They include contradicting information, compounding data quality issues, latent bias in the data and more. However, in this article, I want to focus on two specific issues closely impacting our identity trust assessment: veracity of data and diminishing returns.
The veracity of data
Data is not produced in a lab, nor is it conjured from thin air. There is always a process behind the data. It’s generated as a byproduct from a set of consumer activities or interactions. And, some activities result in data that is more valuable than others.
In the identity and fraud space, this means that due to the nature of the interactions, not all data have the same level of trustworthiness. For example, identity data from authoritative sources, such as Fair Credit Reporting Act (FCRA) credit data, are inherently more trustworthy in corroborating identity and associated insights than data collected from unregulated sources.
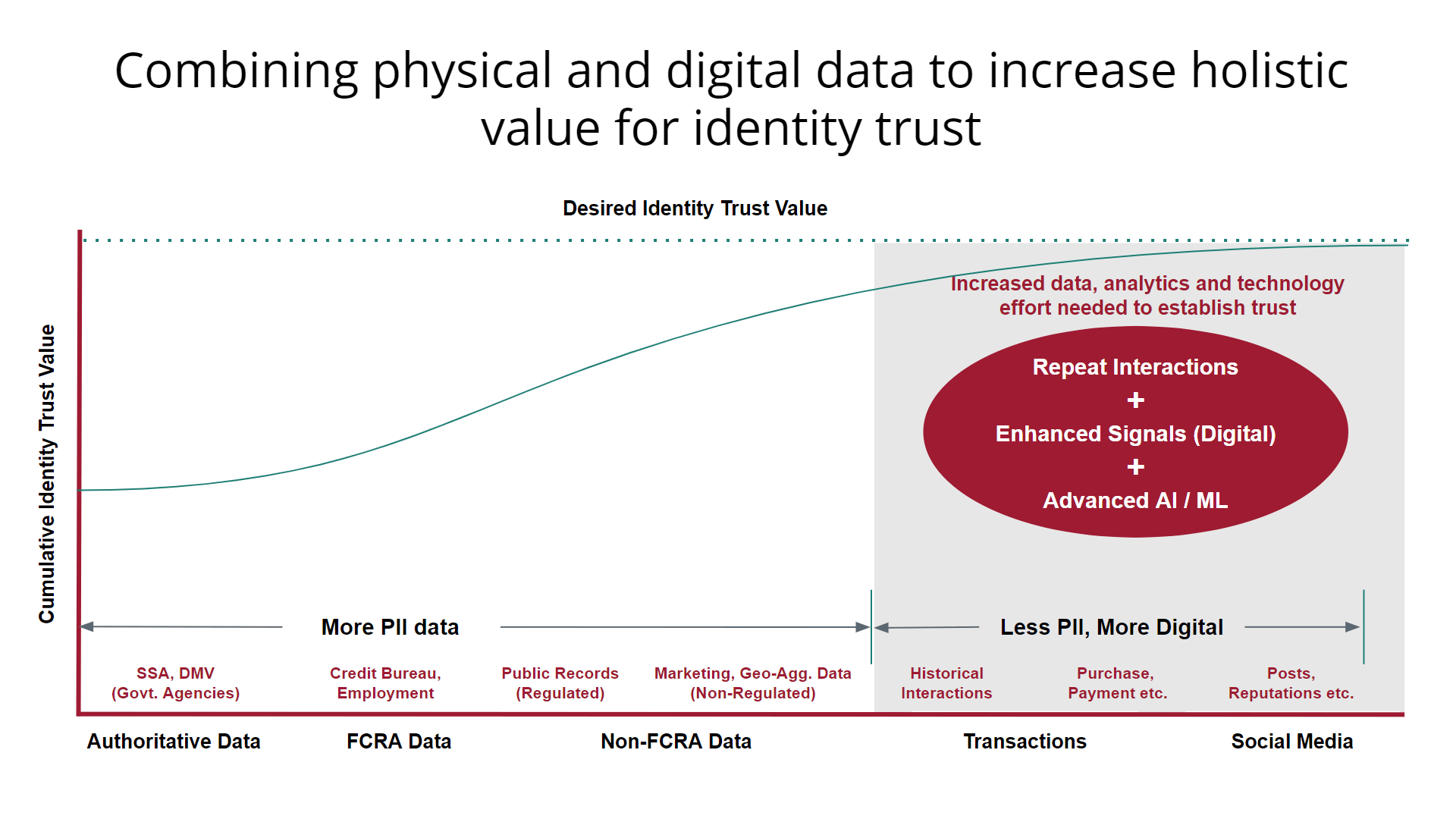
Across the bottom of the chart above, we see multiple data sources at varying trust levels. The direct-from-government data sources, such as Social Security Administration and Department of Motor Vehicles, typically include high levels of personally identifiable information. This increases their trust value from the start. Other types include public records, marketing lists, transactional data and even self-provided social media data, all of which are premium data sources for establishing identity trust. However, this data must first be enhanced to increase its trust value. We do this by collecting more interaction data, repeat observations and the application of artificial intelligence (AI) and machine learning (ML) techniques to key, link and resolve identities.
For example, consumer interactions produce rich meta-data. This includes context of the interaction (e.g. applying for a loan), associations with other elements (e.g. same phone but different email address) and feedback outcomes (e.g. successful attempt using one-time-passcode). By capturing and organizing the meta-data in an efficient manner, it is then possible to apply AI to establish baseline behaviors, predict intent and deliver precise assessments in milliseconds. As a result, it meets today’s rigorous business requirements. In turn, by iteratively applying advanced techniques like these and through constant experimentation and testing, we can increase trust levels and reduce false positives. This happens while increasing the coverage and confidence of the assessment.
Given the evolving state of identity and fraud, it’s also important to consider the provenance of different data sources. That means where the data comes from and the inputs, processes and methodology that produced it. Think of provenance as the data’s “pedigree.” Establishing and maintaining auditable data provenance is a critical step in determining its value and the role it plays, if any, in establishing identity trust. Thus, by incorporating identity insights from multiple sources in the right manner, our ability to assess trust levels of identities is significantly enhanced in coverage, as well as in accuracy.
Diminishing returns
As observed in certain economic activities, the value derived from multi-source data also suffers from the law of diminishing returns. Stated simply, as you add more sources of data, the marginal actionable insight you gain starts to decrease. In addition, key metrics can offset the gain in the marginal insight. These include an increase in cost, expected losses and response time, or decrease in customer value and profit. There are several reasons why this may happen. Most commonly, it is because at some level the data sources begin to have increasing overlap with each other. This occurs either in the population they cover or in the correlated behaviors they capture. So, this is where the ingenuity of the data science team comes into play. They will determine how much more actionable insights can be derived from the data. They'll base their decision on their fundamental understanding of the data, its provenance and the ability to correlate consumer behavior to the identity trust outcomes.
The Efficient Frontier Theory
In the video below, you'll see a real scenario of data assets evaluated to improve the identity trust rate. This illustrates several data strategies, essentially different combinations of data assets, on the Efficient Frontier. The Efficient Frontier theory suggests that successful optimization of the return versus risk paradigm should place a portfolio — or in this case, a data strategy — along the Efficient Frontier line.
As you can see, there are multiple objectives that are conflicting; therefore, it requires a delicate balancing act. The data scientists must use experiments and rigorous analysis to maximize identity trust while minimizing cost, false positives and other metrics. As you increasingly rely on data insights, here are a few takeaways to consider:
- Multidata assets are essential to reduce uncertainty in the constant and rapidly evolving state of identity and fraud.
- Data perfection requires bringing together not just more data, but the right kind of data.
- Establishing data provenance is key to understanding the trustworthiness of data.
- Employ more data and better AI methods to improve varying trust levels in data.
- Mere data accumulation is not sufficient; you must also organize it in the right way to extract value and gain actionable insights.
- Multidata means more potential insights, but it also requires analytically creative approaches to properly harness actionable insights that can make impactful decisions.
- Use or build better AI to manage multiple objectives that can be contradictory.
Next in our series, I’ll focus on next-generation analytic methodologies and techniques that help detect fraud and maximize identity trust. We’ll explore how the right algorithms, models and features can help reduce uncertainty and improve decisioning confidence. And be sure to check out my other posts:
- Multisource Data Helps Reduce Uncertainty in Identity Trust
- How Effective is your Approach to Assessing Identity Trust?
Recommended for you
